
软件介绍
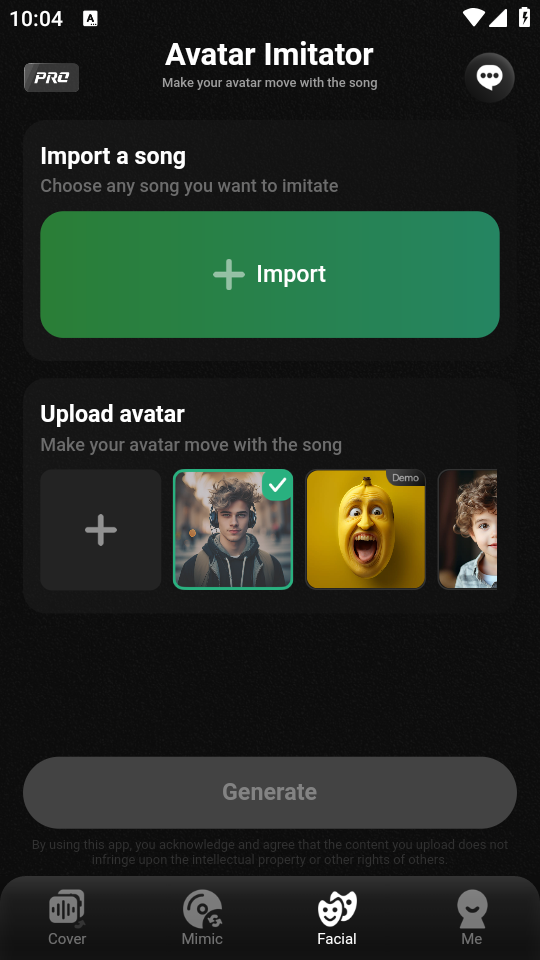
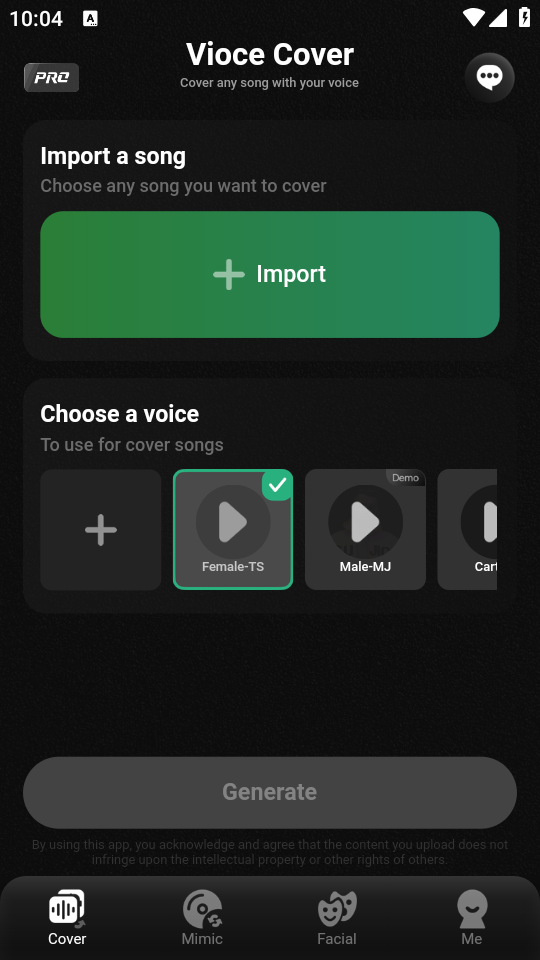
 VoiceFun是一款集声音克隆、AI配音、虚拟形象驱动于一体的创意型多功能配音软件。用户只需上传自己的声音样本和头像图片,即可通过其自研的尖端AI算法,快速生成专属声音模型,并实现人声替换、AI唱歌、唇形同步动画及表情丰富的虚拟人视频合成,让普通用户也能轻松创作出专业级的个性化音视频内容。
VoiceFun是一款集声音克隆、AI配音、虚拟形象驱动于一体的创意型多功能配音软件。用户只需上传自己的声音样本和头像图片,即可通过其自研的尖端AI算法,快速生成专属声音模型,并实现人声替换、AI唱歌、唇形同步动画及表情丰富的虚拟人视频合成,让普通用户也能轻松创作出专业级的个性化音视频内容。
软件优势
- 一键创建高保真个人声纹模型,支持自然流畅的人声替换与AI演唱
- 头像驱动技术精准匹配音频节奏,实现逼真的口型同步与情感化面部动画
- 零门槛创意平台,兼顾配音、翻唱、虚拟出镜等多场景,满足多样化表达需求
- 端到端本地+云端协同处理,兼顾隐私安全与生成效率
- 高度个性化定制,支持风格调节、语速/音调微调及多模板自由组合
使用教程
- 注册账号后进入「我的声音」,按提示录制3段各15秒清晰语音(建议安静环境)
- 在「形象工坊」上传正脸高清头像,选择预设动画风格或启用自动表情增强
- 导入目标音频(如歌曲、台词),选择已训练的声音模型,点击「智能合成」生成结果
- 预览并使用内置编辑器调整唇动精度、情绪强度或背景音乐混音比例
- 导出高清MP4视频或分离音轨,支持一键分享至主流社交平台
更新日志
【v2.3.0|2024年6月】新增「多角色对话模式」,支持单音频驱动多个虚拟形象轮番说话;优化中文方言识别能力,粤语、川普配音自然度提升40%;修复部分安卓设备头像渲染偏色问题。【v2.2.1|2024年4月】上线「声线保护」功能,可加密存储个人声模;新增5款国风/赛博朋克主题虚拟形象皮肤;提升长音频(>5分钟)合成稳定性。































